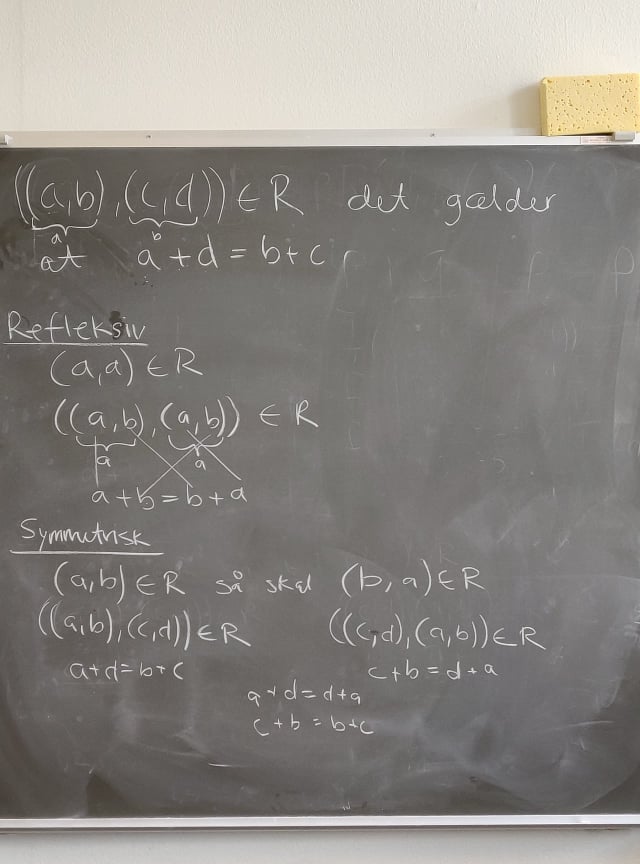Karakter: 12
(mundtlig eksamenen og trak nr. 5 – induktion. Men er 99 % på at resten af notaterne også står til et 12 tal)


p | q | (p ^ q) | (p ^ q) -> p |
true | true | true | true |
true | false | false | true |
false | true | false | true |
false | false | false | true |
Tegn ovenstående
^ = conjunktion
V = disjunktion

![]()
Forklaring:

Ovenfor ses hans forklaring.
En tautalogi betyder at den altid er sand.
Som vist før er en implikation kun falsk, hvis første del er sand og anden del er falsk.
Dvs. at (p ^ q) skal være sand og p skal være falsk.
Men det er jo et paradoks, fordi hvis p skal være sand kan den jo ikke også være falsk. Så det kan ikke ske, så derfor er den altid sand.

Grundmængde = univers
A og b:

A: der eksisterer en x-værdi, hvor p(x) er sand.
B: For alle x-værdier gælder det at p(x) er sand.
C: Der eksisterer en x-værdi hvor p(x) ikke er sand.
D: ikke alle x, gør at p(x) er sand
(så d betyder det samme som c)
C: ¬p(1) V ¬p(2) V ¬p(3) V ¬p(4)
F: ¬(p(1) ^ p(2) ^ p(3) ^ p(4))
Yderligere forklaring:
Her bruger vi bare de morgans lov. (så det til venstre er det samme som det til højre)
![]()

Forklaring: Uden negation ville sætningen være: For alle x gælder det at p(x) er sand. Dvs. negationen er jo bare at det ikke er gælden for alle x-værdier. Dvs. at der skal mindst eksistere en x-værdi, hvor p(x) ikke er sand. Og det er jo det samme som i opgave c.
Hjælpelærer forklaring: (når vi sætter negation til er det det samme som at sætte parentes rundt om sætningen til højre og sætte negation til det.


Kvantor =
Logiske konnektiver = ^, V,
b): ¬∀y∃xP(x, y)
forklaring: Det er ikke for alle y-værdier at der eksisterer en x-værdi, hvor p(x, y) er sand.
Vi bruger de morgans lov:

¬∀y∃xP(x, y) ∃y¬∃xP(x, y) ∃y∀x¬P(x, y)
Der eksisterer en y-værdi, hvor alle x-værdier, gør p(x, y) usand.
c)
Det er ikke for alle -værdier, der for alle -værdier gælder at er sand.
Der eksisterer en y-værdi for en -værdi, som gør ikke er sand.


Potensmængden er mængden af alle delmængder. Dvs. i mængden A er potensmængden alle delmængder af A.
A = {1, 2}
P(A) = {ø, {1}. {2}, {1, 2}}
Først har vi ø, idet ø altid er et subset til mængder, da den passer ind i alle. (ø er nemlig den tomme mængde, dv.s {}.) Herefter har vi {1} og {2} og så har vi {1, 2} idet et set altid er et subset til sig selv. (fordi et set jo passer ind i sig selv).
For at tjekke om jeg har fundet alle delmængder så udregner jeg kardinaliteten af potensmængden, og hvis den stemmer overens med det antal subsets jeg har fundet, så ved vi at altallet i potensmængden hvert fald er rigtig.
Kardinaliteten kan udregnes således:

I A er der 2 elementer (1 og 2), og er 4. Derfor ved vi at vi har alle elementerne i potensmængden nu, da vi har 4.
B = {a, b, c}
P(B) = {ø, {a}, {b}, {c}, {a, b}, {a, c}, {b, c}, {a, b, c}}
Her gør vi det samme som forrige gang. Forskellen her er bare at der er lidt flere mængder i. Kardinaliteten er 2^3 = 8. Vi har også 8 delmængder i vores powersæt så antallet er hvert fald rigtigt.

det er 1 og 0, fordi de enten er medlem af mængden eller ikke medlem af mængden.
A | B | C | B ∩ C | A U (B ∩ C) | A U B | A U C | (A U B) ∩ (A U C) |
1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
∩ = fællesmængden (dvs. Der hvor de overlapper) (Der hvor begge er 1)
U = foreningsmængden (dvs. både den enes og den andens mængde) (Der hvor den ene eller den anden er 1)
(minder lidt om sandhedstabeller)
A | B | C | B ∩ C | A U (B ∩ C) | A U B | A U C | (A U B) ∩ (A U C) |
1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Som vi kan se er de lig med hinanden.
Venn-diagrammer:

![]()
Og så bare lav venn diagrammerne.

Som det kan ses på billederne er begge sider af lighedstegnet altså ens.


Bare tegn graferne ligesom det her:

A: er injektiv fordi ingen af funktionerne har samme resultat. Dvs. resultaterne er b, a, c og d. Og er derfor one-to-one.
C: er ikke injektiv, fordi både f(a) og f(d) giver d. Det er altså ikke one-to-one.

Dvs: Alle s og alle a tilhører settet A. Og hvis s er forskellig fra t jamen så skal f(s) også være forskellig fra f(t).

Definitionsmængden er her: Adam, chou osv..
![]()
A: er onto fordi værdimængden og dispositionsmængden er ens. Dvs. alle medlemmer af dispositionsmængden er et billede af et element i definitionsmængden. Derfor er den onto. (dvs. den er faktisk bijektiv fordi den både er onto og one-to-one)
B: Er ikke onto fordi resultaterne er d, b, c, d. Dispositions var jo fra a, b, c, d og a er ikke et billede af af et element i definitionsmængden. Derfor er den ikke onto.
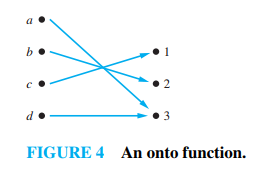
Onto: værdimængde = dispositionsmængde
For some functions the range (værdimængde)(1, 3, 4, 5) and the codomain (dispositionsmængde) (1-5)are equal. That is, every member of the
codomain is the image of some element of the domain (definitionsmængde) (a-d). Functions with this property are called onto functions

A | B | C |
|
|
|
bijektiv | Ingenting | Onto |
Injektiv fordi at der ikke er 2 x-værdier der har samme y-værdi (strengt voksende) | Ikke onto, for den ikke går til -uendelig. | Onto fordi alle v-værdier bliver ramt |
Onto fordi alle y-værdier bliver ramt. | Ikke injektiv, fordi flere x-værdier har samme y-værdi. | Ikke injektiv, fordi flere x-værdier har samme y-værd |

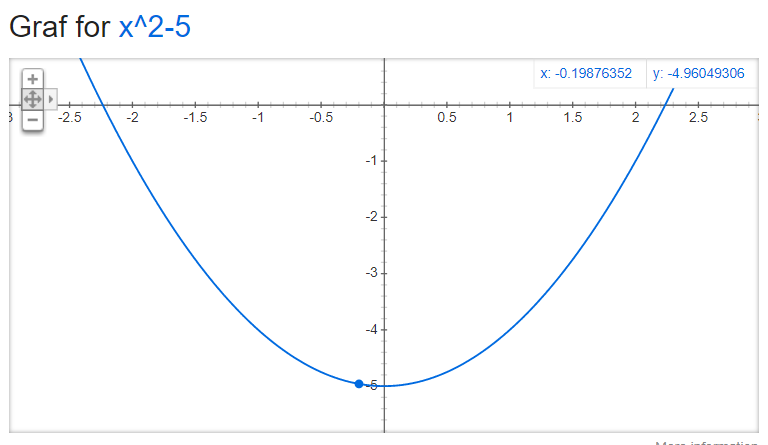

Yderligere hjælp: y-akse: dispositionsmængden x-akse: definitionsmængde graf: værdimængde

En strengt voksende funktion er altid injektiv (one-to-one).
Funktionen er surjektiv (onto) hvis dispositionsmængden er lig værdimængden. (dvs. der skal være noget der peger på samtlige mulige værdier).Dvs. for ethvert element b i B eksisterer der et element i A som er tildelt b.
Bijektiv er bare begge dele. Dvs. for hvert element i B er der præcis et element i A som er tildelt det element.
A:

Denne funktion er bijektiv, fordi der for hvert element i dispositionsmængden (alle reelle tal) er der præcist et element i definitionsmængden som er tildelt det element.
B:

Definitionen for injektiv var jo det her:

Denne graf er altså ikke injektiv, fordi at der er situationer, hvor s og t er forskellig fra hinanden men f(s) og f(t) er ens. Fx er f(1) og f(-1) jo det samme.
Definitionen for onto var:
Dvs. for ethvert element b i B eksisterer der et element i A som er tildelt b.
Grafen går nemlig op til uendelig, men den går ikke ned til -uendelig. Den går kun ned til -5. Derfor er værdimængden altså ikke lig med dispositionsmængden, så derfor er den heller ikke onto.
C: tredje grads polynomium

Denne graf er onto men ikke injektiv.


Med lineær søgning: (bare gør sådan her)


Binær:
Deler den op på midten, sammenligner med sidste element i første del, hvis større, hvis mindre ved man at elementet er i første del. Så fortsætter man bare med at dele op.
Listen hed: 1, 3, 4, 5, 6, 8, 9, 11
Eks:


Binærsøgning fungerer kun på sorterede lister.
Det fungerer således at man deler listen op i midten og så sammenligner vi søgenummereret med sidste element i første del.
Listen hed: 1, 3, 4, 5, 6, 8, 9, 11
Og vi vil søge efter 9.
Derfor deler vi den op i 1, 3, 4, 5 og 6, 8, 9, 11
Herefter sammenligner vi 9 med sidste element i første del, dvs. 5.
9 er større end 5 så derfor ved vi at 9 er i sidste del.
Derfor deler vi listen op igen så vi har 6, 8 og 9, 11
Sammenligner igen med sidste element i første del, dvs. 8. 9 er større end 8 så derfor ved vi at elementet er i sidste del (hvis det overhovedet er der).
Vi deler 9 og 11 op i to lister og sammenligner igen med sidste element i første del, dvs. 9.
Nu er i lig med j, så derfor stopper loopet.
X er lig med ai (a7), så derfor ved vi at 9’s placering i listen er nummer 7.
Derfor er den nu færdig.


Algoritment har flere iterationer. Den første iteration sætter det største element på den sidste plads, den anden iteration sætter det næststørste element på den næstsidste position osv.
I hver iteration er der flere trin, hvor vi bare bytter rundt på elementer, hvis de ikke er i den rigtige rækkefølge.

Listen hed: 6, 2, 3, 1, 5, 4



Listen hed: 6, 2, 3, 1, 5, 4

I en kø (queue) slettes elementerne ifølge FIFO. (First in, first out). (dvs. Bare en normal kø ligesom mcdonalds fx).
Der fjernes 2 elementer. De første 2 der blev sat ind var 3 og 5. Så derfor er det de 2 der bliver fjernet.
Dvs. køen så bliver: 7, 10, 9
Så bliver der indsat 8 og 12, så køen er nu: 7, 10, 9, 8, 12.
Stack:
Stack er en datastruktur hvor de enkelte elementer slettes ifølge LIFO. (last in, first out). (at slette elementer kaldes generelt for pop).
Dvs. stack er bare ligesom en stak tallerkener, hvor du er nødt til at fjerne de øverste før at du kan fjerne de nederste tallerkener.
Stacken var: 3, 5, 7, 10, 9
Der fjernes 2 elementer, dvs. dem der sidste blev tilføjet bliver fjernet. Derfor fjerner vi nu 10 og 9.
Stakken er derfor nu: 3, 5, 7
Herefter indsætter vi 8 og 12. Derfor er stakken: 3, 5, 7, 8, 12.


Vi ved at formlen er gældende for n = 1,2,3,4 men vi vil gerne vise at den er gældende for alle positive heltal så derfor bruger vi induktion (svag) .
Her sætter vi 1, 2, 3, 4 ind på n’s plads i forskriften.
Som det ses på resultaterne er tælleren altså det samme som nævneren minus 1.
Og nævneren starter på 2 og bliver herefter ganget op i takt med at n stiger. Derfor må nævneren være 2^n. Formlen bliver derfor:
Nu vil vi bruge svag induktion til at bevise den formel vi fandt frem til:
Formlerne er: og
Vi vil nu vise at de er ens for n = 1.
Basistrin: f(1) = Så den er hvert fald korrekt.
Vi antager at for n = k er følgende sandt:
=
Baseret på denne antagelse vil vi nu bevise formlen også er sand for n = k + 1
Udskifter k med k +1
=
(Vi arbejder nu på venstre side, så højre side lader vi bare stå her)
Ifølge vores antagelse kan første del af venstre side skiftes ud således:
(forklaringerne står ude til højre)
Her indsættes 2 i første del for at få fælles nævner på begge brøker (+1 tilføjes, da den ganges med sig selv en gang mere – regnereglen ).
2 ganges på i parentesen.
+1 tilføjes, da den ganges med sig selv en gang mere og resten udregnes.
vil derfor være sand, idet
Derfor er gældende for alle positive heltal (integers).

A:
Dette er basistrinnet for induktionen. Her ser vi om vi kan få henholdsvis 18, 19, 20 og 21 cent ved en kombination af 4-cents og 7-cents.
18 cent: 2*7-cent + 4-cent
19 cent: 3*4-cent + 7-cent
20 cent: 5*4-cent
21 cent: 3*7-cent.
Vi har nu bevist at udsagnene p(18), p(19), p(20) og p(21) er sande.
B:
Induktionshypotesen for beviset:
er sand for , hvor er en integer defineret .
(n er det vi ved, og k er det vi vil finde.)
Vi antager at p(18), p(19, p(20), p(21) … P(k) er sand, og derfor kan man få frimærke værdier for 21 og opefter med 4- og 7- cents frimærker.
C: I beviset skal vi bevise følgende:
hvis p(18), p(19), p(20), …, p(k) er sand, så er p(k+1) også sand.
D: fuldend induktionstrinnet
måske tegn noget alla det her

Ved at benytte induktionshypotesen, kan vi antage at er sand, da hvis vil . vil derfor være sand og der kan benyttes 4-cents og 7-cents til danne denne værdi, hvilket er bevist i basistrinnet.
For at lave frimærker af vil der derfor kun skulle tilføjes en 4-cent til det, der skulle benyttes ved . Altså der skal tilføjes 4 til 18 for at få 22.
P(22) er sand fordi vi i basistrinnet ved at p(18) var sand, og derfor kan vi tilføje en 4-cent og få 22.
P(23) er sand fordi vi i basistrinnet ved at p(19) var sand, og derfor kan vi tilføje en 4-cent og få 23.
P(24) er sand fordi vi i basistrinnet ved at p(20) var sand, og derfor kan vi tilføje en 4-cent og få 24.
P(25) er sand fordi vi i basistrinnet ved at p(21) var sand, og derfor kan vi tilføje en 4-cent og få 25.
P(k+1) – vi kan blive ved at med tilføje 4-cent.
Så så længe p(k-3) er sand, så er p(k+1) også sand. (idet vi bare kan tilføje en 4-cent)
Og vi ved jo at , så p(k-3) er derfor altid indenfor begræsningerne i hypotesen.
Vi er nu færdige med beviset.

E:
Det beviser at det er sandt, idet det illustrerer at når vi kan få 18, 19, 20 og 21 cent bed brug af 4-cents og 7-cents, så kan vi få alle cent på et brev derfra, idet vi bare kan tilføje en 4-cent frimærke.
Note:
The difference between weak induction and strong indcution only appears in induction hypothesis. In weak induction, we only assume that particular statement holds at k-th step, while in strong induction, we assume that the particular statment holds at all the steps from the base case to k-th step.

(opgave) Giv en rekursiv definition for her af de to talfølger hvor og hvor
Rekursion bruges til at definere nye værdier til elementer på baggrund af værdier fra tidligere elementer.
Her opskrives og og relateres til hinanden. Hvis det kan gøres med det samme, så er vi allerede ved rekursionstrinnet.
Basistrin
Det er givet at . Herefter udregnes den mindste værdi for sættet for at finde .
Tilføj flere eksempler
Rekursionstrin
Nu indsættes som definitionen på , derfor (altså n-1 i stedet for n i )
Derfor er og deraf (idet an jo var det samme som 4*n, altså )
De to værdier er nu i relation til hinanden.
, da vi har fået opgivet kriteriet i opgaven, og derfor ikke kan gå under 1.
Evt. sæt et eksempel ind, som fx a5 = a4 + 4
Basistrin
Det er givet at . Herefter udregnes den mindste værdi for sættet for at finde .
Rekursionstrin
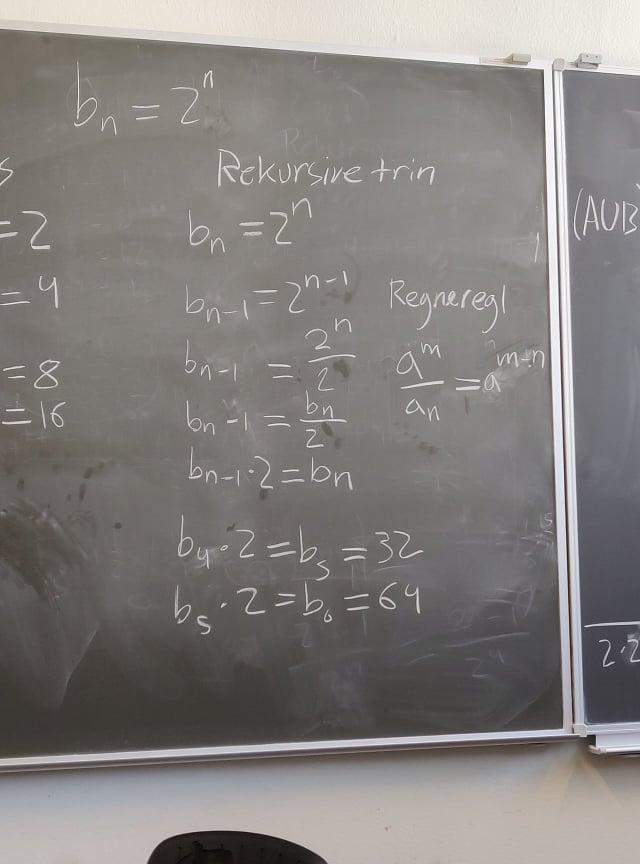
potens er jo hvor man ganger tallet med sig selv. Fx 23 = 2*2*2, 23-1 er derfor 2*2 – altså det samme som at dividere med 2.
Da indsættes dette i ovenstående
, derfor vi vil have bn til at stå alene og kan derfor finde den ved at gange med 2 på begge sider
De to værdier er nu i relation til hinanden.
, da vi har fået opgivet kriteriet i opgaven, og derfor ikke kan gå under 1.
(5.3, 29) Lad være mængden af heltalspar defineret rekursivt ved
Basistrin:
Rekursionstrin: Hvis , så vil og
- Hvilke elementer i kan fås ved højst at benytte basistrin samt det rekursive trin højst to gange?
i sættet, derfor benyttes de oplyste udregninger i rekursionstrinnet til at finde flere talpar.

– Her sættes det ind i et træ, for at vise hvor mange forskellige værdier der kan blive gå igennem 2 gange.
Første rekursionstrin
Ud fra basistrinnet vil vi kunne finde følgende værdier ud fra til mængden ved at benytte udregningerne i rekursionstrinnet:
Andet rekursionstrin
Disse giver os muligheden for at finde flere elementer på baggrund af de allerede fundne:
giver følgende elementer til mængden:
giver følgende elementer til mængden:
giver følgende elementer til mængden:
Nogle af elementerne går dobbelt – de sorteres fra ved nedskrivningen (de er der kun for gennemgangens skyld).
Elementerne, der kan fås ved højst at benytte basistrin og rekursionstrinnet to gange, er derfor:
I det første trin fås:
I det andet trin fås:
(b) Benyt strukturel induktion til at vise, at der for alle talpar (a, b) ∈ S gælder, at a ≤ 2b.
Basis: (0,0)
0 ≤ 2 · 0
Rekursiv del:
Step 1: Fra det rekursive trin (a og b) sættes det ind i udsagnet a ≤ 2b
Step 2: Antag at a ≤ 2b altid er korrekt. Her åbnes () ved at gange 2 ind.
– Hvis det holder for (a, b), så holder det også for alle nye elementer der laves i (a, b) i den rekursive del
(a, b+1) ∈ S = a ≤ 2 (b+1) = a ≤ 2b+2 større
(a+1, b+1) ∈ S = a+1 ≤ 2 (b+1) = a+1 ≤ 2b+2 større
(a+2, b+1) ∈ S = a+2 ≤ 2 (b+1) = a+2 ≤ 2b+2 lig med
I forhold til træet der giver det også mening. Det sted hvor a er størst forhold til b, er i højre side af træet. Her vil a altid være dobbelt så stor som b, og derfor vil a ≤ 2b jo også holde, idet det vil være lig med hinanden. (vis evt. på træet)
Forskellen op hver side af ligningen vil altid stige (med mindre man bruger sidste, som jo er lig med), derfor vil det altid være gældende når man gør det rekursivt. Det sted, hvor forskellen er mindst er jo i basistrinnet.
Spørgsmål 7. Emne: Rekursive algoritmer (se dmg 14)
Litteratur: Afsnit 5.4
(opgave) Sorter følgende liste vha. Merge Sort:
7, 1, 5, 2, 11, 6, 8, 9, 3, 10
Rekursionstrinnet i Merge sort er, hvor de input-listen deles op i to mindre lister. Først anvendes MergeSort proceduren til sortere de små lister (splitte dem op). Herefter anvendes Merge til at flette listerne sammen igen i output-listerne.

På den første del af sorteringen benyttes nedenstående procedure for at adskille de forskellige tal for at sortere dem i input-listen (de bliver små sorterede lister). Dette gøres for hvert skridt i sorteringen. Hvis der er et ulige antal af tal, så er det lige meget hvilken liste den bliver tilføjet til.

Forklaring MergeSort: Listen med en usorteret talrække.
Antallet af elementer i talrækken = .
= halvdelen af talrækken (da ).
= den første del af talrækken frem til .
=anden del af talrækken, hvor hvert tal er afhængig af placering.
På den sidste halvdel benyttes nedenstående til at sorterer rækkefølgen i listerne. Den vil sammenligne de to lister og derved sortere dem i output-listen (samles i en sorteret liste). Dette sker for hvert trin i den nederste del – f.eks. ved 7 og 1, som sorteres til 1, 7, så tages 1,7 og 5 osv.

(5.4, 50) Sorter følgende liste vha. Quick Sort:
3, 5, 7, 8, 1, 9, 2, 4, 6
Ved quicksort udpeges et element i listen til at være et ”delelement” (pivot), hvor de andre elementer sorteres i forhold til det. Det er lige meget hvilket element, der er delelement.


Hvis listen er lig eller mindre end 1, så er listen sorteret på forhånd.
Hvis ikke, så sorteres listen ud fra første element i listen (pivot), hvor sorteringen starter fra andet element i listen til listen slutter . Derefter sorteres listen ud fra det første element til to forskellige lister afhængig af om de forskellige elementer er mindre eller større end . Derefter sorteres de fundne lister på samme måde indtil alle listerne er sorteret og de kan samles i en sorteret liste.
Hvis der sorteres manuelt, så kan der bare vælges et eller andet tal og sortere ud fra.
Det er ikke til at sige, hvor mange gange det kræver at lave en quicksort.
3, 5, 7, 8, 1, 9, 2, 4, 6
Pivot 3.
1 2 3 5 7 8 9 4 6
Delelementer 1 og 5 sorteres ud fra:
1 2 3 4 5 7 8 9 6
Sorteres ud fra delelementerne 4 og 7.
1 2 3 4 5 6 7 8 9
Sorteres ud fra delelementet 8.
1 2 3 4 5 6 7 8 9
Listen er hermed sorteret.

A: Her er matrix repræsentationen af R.
De steder der har en relation er 1 og resten er 0.
(husk at fx (1, 2) betyder række 1, kolonne 2 – ikke omvendt)
1 | 2 | 3 | 4 | |
1 | 0 | 1 | 0 | 1 |
2 | 0 | 0 | 1 | 0 |
3 | 0 | 0 | 0 | 1 |
4 | 0 | 0 | 0 | 1 |
B: Her er den orienterede graf som repræsenterer R.
(fx (1, 2) bliver bare vist som en pil fra 1 til 2)


Orienteret graf:
– Er reflektiv hvis alle punkterne har en loop på sig selv. Altså ligesom nummer 4 har.
- (fx (4, 4) som har en løkke på sig selv)
-Er symmetrisk hvis der for alle pile også går en pil i den modsatte retning. Dvs. hvis der er en relation fra et punkt a til et punkt b, skal der også være en relation fra punkt b til punkt a.

Eks på symmetrisk:
-er antisymmetrisk hvis der for alle relationer (a, b) gælder at der ikke findes en (b, a). Dvs. pilene må ikke gå i modsatte retning, de må kun gå den ene vej. (med mindre at a = b)
– dvs. denne orienterede graf er faktisk antisymmetrisk.
Matrixrelation:
Viser den lige igen:
1 | 2 | 3 | 4 | |
1 | 0 | 1 | 0 | 1 |
2 | 0 | 0 | 1 | 0 |
3 | 0 | 0 | 0 | 1 |
4 | 0 | 0 | 0 | 1 |
Den er reflektiv hvis matricen har 1’taller på alle diagonal-indgangene.

Den er symmetrisk hvis indgangen (i, j) er lig med indgangen (j, i). Altså hvis der findes en (a, b) findes der også en (b, a).

Man kan også se det som at matricen skal være spejlvendt i den røde streg, som ses her:

Den er antisymmetrisk hvis højst en af (i, j) og (j, i)-indgangene er 1. Eks:

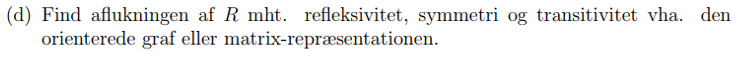
Når man aflukker R skal man tilføje flere elementer til R, sådan så man får den egenskab som man gerne vil have, altså reflektiv, symmetrisk eller transitiv.
Reflektiv | Symmetrisk | transitivt |
|
|
|



(husk at sætter den sammen)
Her vil jeg vise det ved hjælp af en orienteret graf:
Nuværende graf:
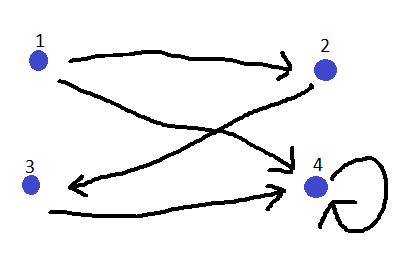
Vi starter med at finde den reflektive. Her skal vi blot sætte en løkke på hvert punkt.
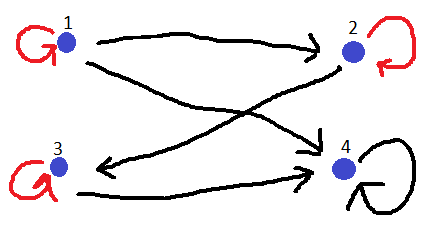
Hvis vi vil finde den symmetriske skal vi blot sætte pile tilbage til de steder hvor der er pile:

Den transitive er dog lidt mere tricky:

Her sætter vi de forskellige relationer ind. R1 er den vi startede med. R2 er der hvor vi indsætter transisitve. Altså der skal fx fra en pil fra 1 til 3, fordi vi har (1,2) og (2, 3) i relationen og skal derfor jo have (1, 3) for at gøre den transitiv.
Og det der er tricky ved denne opgave er at vi har en løkke ved nummer 4. Dvs. i R3 skal vi også have en pil fra 2 til 4, fordi at vi fra 4 jo kan gå over i 4 igen. Så så snart vi har en der ender i 4 skal den også være i de andre r3, r4, r5 osv.
Obs. Ved 4 punkter kan man max komme op på R4 for at finde alle relationerne til at gøre den transitiv.
(man kan nemlig komme ud for at have en firkant hvor alle punkterne peger videre på hinanden. Derfor vil man i r4 ende med løkker i alle punkter).
Aflukning for matrix:
Reflektiv: bare (1,1) (2,2) osv. Nemt
Symmetrisk: den skrå spejlvendt, nemt.
Transitiv:

Forklaring:

(9.5, 13) Lad være relationen på mængden af ordnet par af positive heltal, således at , hvis og kun hvis . Vis, at relationen er en ækvivalensrelation.
En relation på en mængde kaldes en ækvivalensrelation, hvis er refleksiv, symmetrisk og transitiv.
Ækvivalensrelationer: skrives også og og siges at være ækvivalente.
Reflektiv og symmetrisk:

Transitiv:

Refleksiv
, derfor tages det første i mængden
Det skal vises at dette sæt findes i mængden.
Det vides at , derfor tages værdierne, som svarer til disse og sættes ind i stedet.
Sættet findes derfor i mængden.
Symmetrisk
Her gælder at hvis skal .
Derfor skal det vises at hvis så findes også.
Vi ved at gælder, vi tager derfor værdierne fra det andet sæt og indsætter i samme formel.
Hvis vi sætter de to gældende sammen får vi:
De kan sættes sammen, da vi kender værdierne for henholdsvis og .
Dette sæt findes derfor også i sættet.
Transitiv
Her gælder at hvis og , så skal .
Derfor hvis og så skal .
Vi ved at:
Vi skal vise at
Hvis vi isolerer og ud fra de punkter, som vi ved findes i mængden, for at disse sættes ind i ovenstående formel for at bevise at punktet eksisterer i mængden.
De indsættes i formlen:
De findes derfor i mængden.
Relationen er derfor en ækvivalensrelation.
(2) Lad være mængden bestående af alle folk i verden. Er følgende relationer da ækvivalensrelationer?
De overordnede relationer vil være følgende:
Refleksiv Hvis hvert element er relateret til sig selv .
Symmetrisk For alle og elementer i et sæt, hvis er relateret til og er relateret til hvis så vil .
Transitiv Når er relateret til , og er relateret til , så vil også være relateret til hvis og så vil .
(a) Relationen , hvor , hvis er fætter eller kusine til .
A: er vel ikke reflektiv, fordi man ikke er fætter/kusine med sig selv.
Men den er symmetrisk fordi, de mennesker der er din fætter/kusine, der er du jo også deres fætter/kusine.
Den er ikke transitiv, fordi at din fætters/kusines fætter/kusines ikke behøver at være en fætter/kusines som du selv har. Det kommer jo an på om det er på mors eller fars side.
Så den er IKKE en ækvivalensrelation.
(b) Relationen , hvor , hvis og har samme forældre.
Refleksiv
Relationen er refleksiv, da vil have de samme forældre som , altså sig selv. Den er derfor relateret til sig selv.
Symmetrisk
Hvis har samme forældre som vil også have de samme forældre som . De vil være søskende, derfor vil de være relateret.
Transitiv
Hvis og har samme forældre, og har de samme forældre som , så vil også have de samme forældre som . De vil derfor være søskende og derfor være relateret.
Relationen opfylder derfor alle kriterierne som refleksiv, symmetrisk og transitiv, og vil derfor være en ækvivalensrelation.

Sidste ting der giver mening: